系统设计:为什么 Kafka 如此流行?
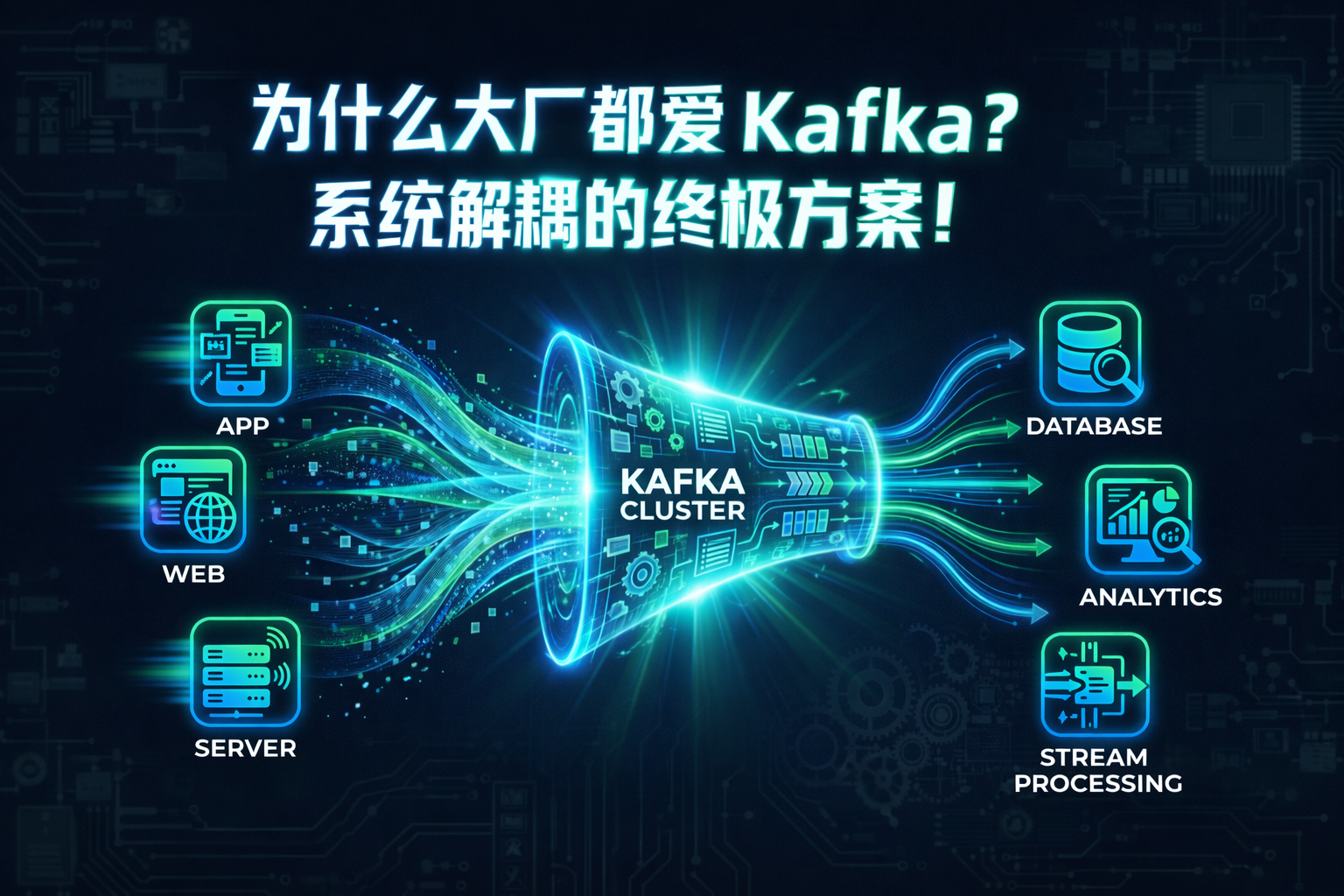
引言
Apache Kafka 已经成为现代分布式系统中不可或缺的组件。LinkedIn、Netflix、Uber 等公司每天使用 Kafka 处理数十亿条消息。作为运维人员,深入理解 Kafka 的架构和工作原理对于系统的稳定运行至关重要。
本文将详细介绍 Kafka 的核心概念、架构设计以及在生产环境中需要注意的权衡取舍。
为什么需要 Kafka?
核心价值
Kafka 解决了分布式系统中的三大核心问题:
1. 系统解耦
在传统架构中,生产者和消费者需要直接通信,这会导致系统间的紧密耦合。Kafka 作为中间层,允许生产者和消费者独立演进,互不影响。
传统模式:
服务A → 直接调用 → 服务B (紧耦合)
Kafka模式:
服务A → Kafka → 服务B (解耦)
2. 流量削峰
在流量高峰期,直接调用可能会压垮下游服务。Kafka 作为缓冲区,可以平滑处理突发流量。
实际案例:电商大促期间,订单服务可能在瞬间接收数万笔订单,Kafka 可以暂存这些消息,让下游服务按照自己的处理能力逐步消费。
3. 事件回放
Kafka 保留历史消息,支持事件回放。这在以下场景中非常有用:
- 调试:重放生产环境的事件流来复现问题
- 故障恢复:系统恢复后重新处理丢失的数据
- 审计:追溯历史事件用于合规审计
- Event Sourcing:基于事件重建系统状态
Kafka 核心架构
基础概念
理解 Kafka 需要掌握以下核心概念:
消息(Message)
Kafka 中的基本数据单元,包含:
- Key:消息键,用于分区路由
- Value:消息内容(实际数据)
- Timestamp:时间戳
- Headers:元数据标头
主题(Topic)
消息的逻辑分类,类似于数据库中的表。例如:
payment-events:支付相关事件user-clicks:用户点击行为order-updates:订单状态更新
分区(Partition)
每个 Topic 可以分为多个 Partition,这是 Kafka 实现高吞吐的关键:
Topic: order-events
├── Partition 0: [msg1, msg2, msg3, ...]
├── Partition 1: [msg4, msg5, msg6, ...]
└── Partition 2: [msg7, msg8, msg9, ...]
分区特性:
- 每个分区是一个有序的、不可变的消息序列
- 消息在分区内追加写入(Append-only Log)
- 不同分区之间的消息顺序无法保证
Broker
Kafka 服务器节点,负责存储和处理消息。多个 Broker 组成一个 Kafka 集群。
消息分区策略
分区策略决定了消息如何分布到不同的 Partition,这直接影响系统性能。
基于 Key 的分区
| |
相同 Key 的消息总是进入同一个分区,保证了顺序性。
热点分区问题(Hot Partition)
错误示例:视频评论系统,如果仅按视频 ID 分区:
热门视频(movie_id=123):
Partition 1: ████████████████████ (过载!)
冷门视频:
Partition 2: ██
Partition 3: █
这会导致某个分区压力过大,其他分区闲置。
解决方案:复合键
| |
这样即使是热门视频,不同用户的评论也会分散到不同分区。
生产者与消费者
生产者(Producer)
生产者负责将消息发送到 Kafka。关键配置:
acks 参数(确认机制)
| |
消费者(Consumer)
消费者从 Kafka 读取消息。核心概念:
Offset(偏移量)
Offset 是消息在分区中的位置标识:
Partition 0:
Offset: 0 1 2 3 4 5
Message: [A] [B] [C] [D] [E] [F]
↑
Consumer offset = 3
消费者通过 Offset 跟踪处理进度:
- 读取消息
- 处理业务逻辑
- 提交 Offset
如果消费者崩溃重启,可以从上次提交的 Offset 继续消费。
消费者组(Consumer Group)
多个消费者可以组成一个消费者组,协作消费同一个 Topic:
Topic: order-events (3 个分区)
Consumer Group: order-processors
├── Consumer 1 → Partition 0
├── Consumer 2 → Partition 1
└── Consumer 3 → Partition 2
特性:
- 组内每个分区只被一个消费者消费
- 不同组的消费者可以独立消费同一个 Topic
- 消费者数量不应超过分区数量
消息交付保证
Kafka 提供三种交付语义:
1. At Most Once(最多一次)
| |
- 特点:快速,性能高
- 风险:如果处理失败,消息丢失
- 适用场景:日志收集、监控指标
2. At Least Once(至少一次)
| |
- 特点:不会丢消息
- 风险:如果提交失败,可能重复处理
- 适用场景:大多数业务场景
- 要求:下游系统需要实现幂等性
3. Exactly Once(精确一次)
使用 Kafka 事务机制实现:
| |
- 特点:最强一致性保证
- 成本:性能开销大,配置复杂
- 适用场景:金融交易、账务系统
高可用与容错
副本机制(Replication)
Kafka 通过副本保证数据可靠性:
Topic: payments, Partition 0
Broker 1 (Leader): [A, B, C, D, E] ← 处理读写
Broker 2 (Follower): [A, B, C, D, E] ← 同步复制
Broker 3 (Follower): [A, B, C, D, E] ← 同步复制
角色说明
- Leader:处理所有读写请求
- Follower:被动复制 Leader 的数据
- ISR(In-Sync Replica):与 Leader 保持同步的副本集合
故障切换
当 Leader 宕机时:
- Kafka 从 ISR 中选举新的 Leader
- 客户端自动切换到新 Leader
- 旧 Leader 恢复后成为 Follower
生产环境建议
| |
这样配置可以容忍 1 个 Broker 故障而不丢数据。
实际应用场景
场景 1:实时数据流处理
Uber 动态定价系统
司机位置更新 → Kafka → 实时计算引擎 → 动态定价
用户打车请求 → Kafka → 供需分析 → 价格调整
Kafka 每秒处理数百万条位置更新,支持实时的供需平衡计算。
场景 2:Event Sourcing(事件溯源)
将系统状态变更记录为事件序列:
订单系统事件流:
1. OrderCreated (订单创建)
2. PaymentReceived (支付完成)
3. OrderShipped (订单发货)
4. OrderDelivered (订单送达)
通过回放事件流,可以重建任意时刻的系统状态。
场景 3:日志聚合
集中收集各个服务的日志:
服务A → Kafka Topic: app-logs
服务B → Kafka Topic: app-logs
服务C → Kafka Topic: app-logs
↓
日志分析系统
(ELK/Splunk)
设计权衡与限制
高吞吐 vs 低延迟
Kafka 优化的是吞吐量而非延迟:
- 吞吐量:可达每秒百万级消息
- 延迟:通常在几毫秒到几十毫秒
不适用场景
| |
对于需要即时响应的场景(如用户登录验证),应该使用 RPC 框架(gRPC、HTTP)而非 Kafka。
顺序性保证
Kafka 的顺序性有限制:
✓ 保证:单个分区内的消息顺序
✗ 不保证:跨分区的全局顺序
示例
Partition 0: [A1, A2, A3] 时间顺序
Partition 1: [B1, B2, B3] 时间顺序
跨分区消费时可能得到:
[A1, B1, A2, B2, A3, B3] 顺序可能打乱
解决方案
如果需要全局顺序,只能使用单个分区(会限制吞吐量)。
运维复杂度
引入 Kafka 会增加系统复杂度:
需要关注的运维点
集群监控
- Broker 健康状态
- 分区 Leader 分布
- 副本同步延迟
- 磁盘使用率
性能调优
- 分区数量规划
- 副本因子设置
- 消费者组平衡
- 日志清理策略
容量规划
- 消息保留时间
- 磁盘空间预估
- 网络带宽需求
运维最佳实践
监控指标
关键指标及告警阈值:
| |
容量规划公式
磁盘容量估算
所需磁盘 = (消息速率 × 消息大小 × 保留时间 × 副本因子) / 压缩率
示例:
- 消息速率:10,000 msg/s
- 消息大小:1KB
- 保留时间:7天
- 副本因子:3
- 压缩率:0.5
所需磁盘 = 10000 × 1KB × 7×24×3600 × 3 / 0.5
≈ 3.6 TB
分区数量建议
分区数 = max(
目标吞吐量 / 单分区吞吐量,
消费者数量
)
# 示例
目标:100 MB/s
单分区:10 MB/s
分区数 ≥ 10
注意:分区数不是越多越好,过多分区会增加:
- 文件描述符消耗
- 选举时间
- 端到端延迟
消息保留策略
| |
故障处理流程
Broker 宕机
| |
消费者 Lag 过高
| |
总结
Kafka 作为现代分布式系统的核心组件,提供了强大的系统解耦、流量削峰和事件回放能力。但在使用时需要注意:
适用场景
- 需要高吞吐量的数据流处理
- 系统间异步解耦
- 事件溯源和 CQRS 架构
- 日志聚合和实时分析
不适用场景
- 需要即时响应的同步调用
- 需要严格全局顺序的场景
- 简单的点对点消息传递(可能有更轻量的选择)
运维关键点
- 合理规划分区数量和副本因子
- 持续监控关键指标(Lag、副本同步状态)
- 定期评估容量和性能
- 建立完善的故障处理流程
理解这些核心概念和权衡,才能在生产环境中充分发挥 Kafka 的价值,同时避免常见的陷阱。
参考资源
本文基于 Kafka 3.x 版本编写,适用于运维人员快速理解 Kafka 的核心概念和生产实践。